Приведу пример распределения прерываний сетевых интерфейсов по ядрам процессора.
Для примера возьму сервер с accel-ppp, трафиком 6Gb/s, 500K+ pps, nat с ipoe и 6000 dchp клиентов.
А также обязательно отключим hyper-threading в BIOS, так как распределение нагрузки на виртуальные ядра может сильно увеличить нагрузку на некоторые физические ядра.
Посмотрим как распределены прерывания на данный момент (команды нужно выполнять от root пользователя):
cat /proc/interrupts
grep ens2f0 /proc/interrupts
grep ens2f1 /proc/interrupts
watch -n 1 cat /proc/interrupts
watch -n 1 grep ens1f0 /proc/interrupts
watch -n 1 cat /proc/softirqs
ethtool -S eth0
Также в реальном времени посмотрим как загружены ядра процессора выполнив команду «top» и нажав «1» и что грузит набрав команды:
perf top
apt install sysstat
sar -u ALL -P ALL 1
Посмотрим равномерно ли идет трафик по прерываниям, должны быть примерно одинаковые значения счетчиков (пример для ixgbe):
ethtool -S ens1f0 | grep .x_queue_._packets
ethtool -S ens1f1 | grep .x_queue_._packets
Для i40e так:
ethtool -S ens1f0 | grep x_packets:
ethtool -S ens1f1 | grep x_packets:
Посмотрим сколько прерываний возможно и активно на сетевом интерфейсе:
ethtool -l ens1f0
ethtool -l ens1f1
Например у меня в сервере стояло два процессора e5-2680 по 8 ядер, двух портовая сетевая плата HP 562SFP+ была в numa0 первого процессора и irqbalance распределил 16 прерываний обеих сетевых интерфейсов на 7 ядер первого процессора, кроме 0 ядра.
Поэтому я сначала указал вручную 8 прерываний вместо 16:
ethtool -L ens1f0 combined 8
ethtool -L ens1f1 combined 8
Приступим к настройке RSS. Назначить прерывание сетевого интерфейса на определенное ядро процессора можно так (где «X» — номер прерывания который отображается в первом столбце /proc/interrupts, а «N» — маска процессора):
echo N > /proc/irq/X/smp_affinity
Я посмотрел в таблице номера прерываний сетевых интерфейсов:
cat /proc/interrupts
Посмотрел как распределил нагрузку irqbalance для первого порта сетевой платы (ens1f0):
cat /proc/irq/47/smp_affinity
cat /proc/irq/48/smp_affinity
cat /proc/irq/49/smp_affinity
cat /proc/irq/50/smp_affinity
cat /proc/irq/51/smp_affinity
cat /proc/irq/52/smp_affinity
cat /proc/irq/53/smp_affinity
cat /proc/irq/54/smp_affinity
Отобразилось:
00000000,00000004
00000000,00000002
00000000,00000020
00000000,00000010
00000000,00000008
00000000,00000020
00000000,00000040
00000000,00000080
Как распределил нагрузку irqbalance для второго порта сетевой платы (ens1f1):
cat /proc/irq/75/smp_affinity
cat /proc/irq/76/smp_affinity
cat /proc/irq/77/smp_affinity
cat /proc/irq/78/smp_affinity
cat /proc/irq/79/smp_affinity
cat /proc/irq/80/smp_affinity
cat /proc/irq/81/smp_affinity
cat /proc/irq/82/smp_affinity
Отобразилось:
00000000,00000008
00000000,00000002
00000000,00000008
00000000,00000008
00000000,00000004
00000000,00000020
00000000,00000040
00000000,00000080
Можно еще посмотреть так PCI address of 0000:04:00.0:
ls -1 /sys/devices/*/*/0000:04:00.0/msi_irqs
Как видим через RSS irqbalance в моем случае распределил нагрузку криво, хотя на zabbix графиках нагрузка было примерно ровная, но простаивало 0 ядро.
Маску процессора можно определить используя bc по формуле:
apt install bc
echo "obase=16; $[2 ** $cpuN]" | bc
Например посчитаем для 28 ядер:
echo "obase=16; $[2** 0]" | bc
echo "obase=16; $[2** 1]" | bc
echo "obase=16; $[2** 2]" | bc
echo "obase=16; $[2** 3]" | bc
echo "obase=16; $[2** 4]" | bc
echo "obase=16; $[2** 5]" | bc
echo "obase=16; $[2** 6]" | bc
echo "obase=16; $[2** 7]" | bc
echo "obase=16; $[2** 8]" | bc
echo "obase=16; $[2** 9]" | bc
echo "obase=16; $[2** 10]" | bc
echo "obase=16; $[2** 11]" | bc
echo "obase=16; $[2** 12]" | bc
echo "obase=16; $[2** 13]" | bc
echo "obase=16; $[2** 14]" | bc
echo "obase=16; $[2** 15]" | bc
echo "obase=16; $[2** 16]" | bc
echo "obase=16; $[2** 17]" | bc
echo "obase=16; $[2** 18]" | bc
echo "obase=16; $[2** 19]" | bc
echo "obase=16; $[2** 20]" | bc
echo "obase=16; $[2** 21]" | bc
echo "obase=16; $[2** 22]" | bc
echo "obase=16; $[2** 23]" | bc
echo "obase=16; $[2** 24]" | bc
echo "obase=16; $[2** 25]" | bc
echo "obase=16; $[2** 26]" | bc
echo "obase=16; $[2** 27]" | bc
У меня получилось:
1
2
4
8
10
20
40
80
100
200
400
800
1000
2000
4000
8000
20000
40000
80000
100000
200000
400000
800000
1000000
2000000
4000000
8000000
Перед изменениями обязательно остановим irqbalance и уберем из автозапуска при старте системы, так как он начнет возвращать свои значения:
systemctl is-enabled irqbalance
systemctl disable irqbalance
service irqbalance status
service irqbalance stop
Соответственно я выполнил команды ниже, чтобы привязать по 8 прерываний обеих сетевых интерфейсов к 8 ядрам процессора:
echo 1 > /proc/irq/47/smp_affinity
echo 2 > /proc/irq/48/smp_affinity
echo 4 > /proc/irq/49/smp_affinity
echo 8 > /proc/irq/50/smp_affinity
echo 10 > /proc/irq/51/smp_affinity
echo 20 > /proc/irq/52/smp_affinity
echo 40 > /proc/irq/53/smp_affinity
echo 80 > /proc/irq/54/smp_affinity
echo 1 > /proc/irq/75/smp_affinity
echo 2 > /proc/irq/76/smp_affinity
echo 4 > /proc/irq/77/smp_affinity
echo 8 > /proc/irq/78/smp_affinity
echo 10 > /proc/irq/79/smp_affinity
echo 20 > /proc/irq/80/smp_affinity
echo 40 > /proc/irq/81/smp_affinity
echo 80 > /proc/irq/82/smp_affinity
Нагрузка на ядра стала чуть ровнее чем в случае с irqbalance.
Посмотрим как настроен RPS (Receive Packet Steering — программный аналог аппаратного RSS), у меня по умолчанию отобразилось 00000000,00000000:
cat /sys/class/net/ens1f0/queues/*/rps_cpus
cat /sys/class/net/ens1f1/queues/*/rps_cpus
RPS я не включал, но он очень полезен когда на сетевом интерфейсе меньше прерываний чем у процессора ядер. Подробнее смотрите в моей статье:
Настройка RPS (Receive Packet Steering)
Как видно на графике, после RSS прерывания распределились еще ровнее, softirq нагрузка на Zabbix графиках шла у каждого ядра почти в одну линию.
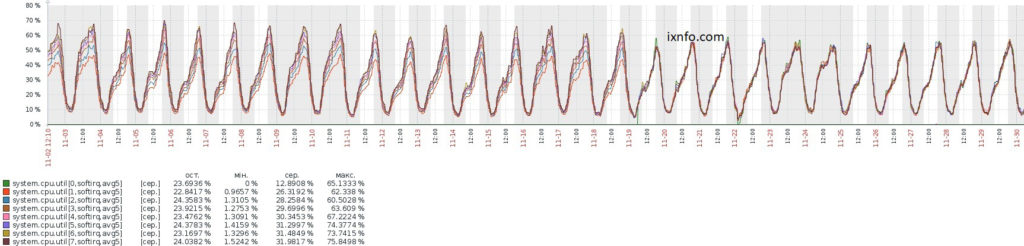
Чтобы изменения не сбросились после перезапуска системы — добавим команды в /etc/rc.local:
/sbin/ethtool -L ens1f0 combined 8
/sbin/ethtool -L ens1f1 combined 8
echo 1 > /proc/irq/47/smp_affinity
echo 2 > /proc/irq/48/smp_affinity
echo 4 > /proc/irq/49/smp_affinity
echo 8 > /proc/irq/50/smp_affinity
echo 10 > /proc/irq/51/smp_affinity
echo 20 > /proc/irq/52/smp_affinity
echo 40 > /proc/irq/53/smp_affinity
echo 80 > /proc/irq/54/smp_affinity
echo 1 > /proc/irq/75/smp_affinity
echo 2 > /proc/irq/76/smp_affinity
echo 4 > /proc/irq/77/smp_affinity
echo 8 > /proc/irq/78/smp_affinity
echo 10 > /proc/irq/79/smp_affinity
echo 20 > /proc/irq/80/smp_affinity
echo 40 > /proc/irq/81/smp_affinity
echo 80 > /proc/irq/82/smp_affinity
Можно посмотреть статистику трафика в реальном времени:
apt install python3-pip
pip3 install netutils-linux
network-top -i 1 -n -1 --dev ens2,ens4
Смотрите также мои статьи:
- Настройка сети в Linux
- Скрипт привязки прерываний сетевой платы Intel к ядрам процессора
- Taskset — привязка процесса к ядрам CPU
- Как узнать на каких NUMA node сетевые интерфейсы
- Как отличить физические ядра процессора от виртуальных
- Мониторинг использования CPU в Zabbix
- Мониторинг PPS (Packets Per Second) в Zabbix
- write error: Value too large for defined data type