I will give an example of the distribution of interrupt network interfaces on the processor cores.
For example, I’ll take a server with accel-ppp, 6Gb/s traffic, 500K + pps, nat with ipoe and 6000 dchp clients.
Also, be sure to disable hyper-threading in the BIOS, since load balancing on virtual cores can greatly increase the load on some physical cores.
Let’s see how the interrupts are distributed at the moment (the commands need to be executed from the root user):
cat /proc/interrupts
grep ens2f0 /proc/interrupts
grep ens2f1 /proc/interrupts
watch -n 1 cat /proc/interrupts
watch -n 1 grep ens1f0 /proc/interrupts
watch -n 1 cat /proc/softirqs
ethtool -S eth0
Also, in real time, let’s see how the processor cores are loaded by executing the “top” command and pressing “1” and what loads by typing the commands:
perf top
apt install sysstat
sar -u ALL -P ALL 1
Let’s see if traffic flows interrupt evenly, there should be approximately the same counter values (example for ixgbe):
ethtool -S ens1f0 | grep .x_queue_._packets
ethtool -S ens1f1 | grep .x_queue_._packets
For i40e like this:
ethtool -S ens1f0 | grep x_packets:
ethtool -S ens1f1 | grep x_packets:
Let’s see how many interrupts are possible and active on the network interface:
ethtool -l ens1f0
ethtool -l ens1f1
For example, I had two e5-2680 processors with 8 cores in each server, the two-port HP 562SFP + network card was in numa0 of the first processor and irqbalance distributed 16 interruptions of both network interfaces to 7 cores of the first processor, except for 0 core.
Therefore, I first manually specified 8 interrupts instead of 16:
ethtool -L ens1f0 combined 8
ethtool -L ens1f1 combined 8
Let’s set up RSS. You can assign a network interface interrupt to a specific processor core as follows (where “X” is the interrupt number that appears in the first column /proc/interrupts, and “N” is the processor mask):
echo N > /proc/irq/X/smp_affinity
I looked at the table of interrupt numbers of network interfaces:
cat /proc/interrupts
I looked at how I distributed the load of irqbalance for the first port on the network card (ens1f0):
cat /proc/irq/47/smp_affinity
cat /proc/irq/48/smp_affinity
cat /proc/irq/49/smp_affinity
cat /proc/irq/50/smp_affinity
cat /proc/irq/51/smp_affinity
cat /proc/irq/52/smp_affinity
cat /proc/irq/53/smp_affinity
cat /proc/irq/54/smp_affinity
It was displayed:
00000000,00000004
00000000,00000002
00000000,00000020
00000000,00000010
00000000,00000008
00000000,00000020
00000000,00000040
00000000,00000080
How to load the irqbalance load for the second port on the network card (ens1f1):
cat /proc/irq/75/smp_affinity
cat /proc/irq/76/smp_affinity
cat /proc/irq/77/smp_affinity
cat /proc/irq/78/smp_affinity
cat /proc/irq/79/smp_affinity
cat /proc/irq/80/smp_affinity
cat /proc/irq/81/smp_affinity
cat /proc/irq/82/smp_affinity
It was displayed:
00000000,00000008
00000000,00000002
00000000,00000008
00000000,00000008
00000000,00000004
00000000,00000020
00000000,00000040
00000000,00000080
You can also see the PCI address of 0000:04:00.0:
ls -1 /sys/devices/*/*/0000:04:00.0/msi_irqs
As we see through RSS, irqbalance in my case distributed the load crookedly, although on zabbix graphs the load was approximately equal, but 0 core was idle.
The processor mask can be determined using bc using the formula:
apt install bc
echo "obase=16; $[2 ** $cpuN]" | bc
For example, calculate for 28 cores:
echo "obase=16; $[2** 0]" | bc
echo "obase=16; $[2** 1]" | bc
echo "obase=16; $[2** 2]" | bc
echo "obase=16; $[2** 3]" | bc
echo "obase=16; $[2** 4]" | bc
echo "obase=16; $[2** 5]" | bc
echo "obase=16; $[2** 6]" | bc
echo "obase=16; $[2** 7]" | bc
echo "obase=16; $[2** 8]" | bc
echo "obase=16; $[2** 9]" | bc
echo "obase=16; $[2** 10]" | bc
echo "obase=16; $[2** 11]" | bc
echo "obase=16; $[2** 12]" | bc
echo "obase=16; $[2** 13]" | bc
echo "obase=16; $[2** 14]" | bc
echo "obase=16; $[2** 15]" | bc
echo "obase=16; $[2** 16]" | bc
echo "obase=16; $[2** 17]" | bc
echo "obase=16; $[2** 18]" | bc
echo "obase=16; $[2** 19]" | bc
echo "obase=16; $[2** 20]" | bc
echo "obase=16; $[2** 21]" | bc
echo "obase=16; $[2** 22]" | bc
echo "obase=16; $[2** 23]" | bc
echo "obase=16; $[2** 24]" | bc
echo "obase=16; $[2** 25]" | bc
echo "obase=16; $[2** 26]" | bc
echo "obase=16; $[2** 27]" | bc
I got the result:
1
2
4
8
10
20
40
80
100
200
400
800
1000
2000
4000
8000
20000
40000
80000
100000
200000
400000
800000
1000000
2000000
4000000
8000000
Before changes, be sure to stop irqbalance and remove it from autostart at system startup, since it will start returning its values:
systemctl is-enabled irqbalance
systemctl disable irqbalance
service irqbalance status
service irqbalance stop
Accordingly, I executed the commands below to bind 8 interrupts of both network interfaces to 8 processor cores:
echo 1 > /proc/irq/47/smp_affinity
echo 2 > /proc/irq/48/smp_affinity
echo 4 > /proc/irq/49/smp_affinity
echo 8 > /proc/irq/50/smp_affinity
echo 10 > /proc/irq/51/smp_affinity
echo 20 > /proc/irq/52/smp_affinity
echo 40 > /proc/irq/53/smp_affinity
echo 80 > /proc/irq/54/smp_affinity
echo 1 > /proc/irq/75/smp_affinity
echo 2 > /proc/irq/76/smp_affinity
echo 4 > /proc/irq/77/smp_affinity
echo 8 > /proc/irq/78/smp_affinity
echo 10 > /proc/irq/79/smp_affinity
echo 20 > /proc/irq/80/smp_affinity
echo 40 > /proc/irq/81/smp_affinity
echo 80 > /proc/irq/82/smp_affinity
The load on the cores has become a little more even than in the case of irqbalance.
Let’s see how RPS (Receive Packet Steering – software analogue of hardware RSS) is configured, I have displayed 00000000,00000000 by default:
cat /sys/class/net/ens1f0/queues/*/rps_cpus
cat /sys/class/net/ens1f1/queues/*/rps_cpus
I did not enable RPS, but it is very useful when there are fewer interrupts on the network interface than the core processor. See my article for more details:
Configuring RPS (Receive Packet Steering)
As you can see on the graph, after RSS interruptions were distributed even more evenly, softirq load on Zabbix graphs went for almost every line for each core.
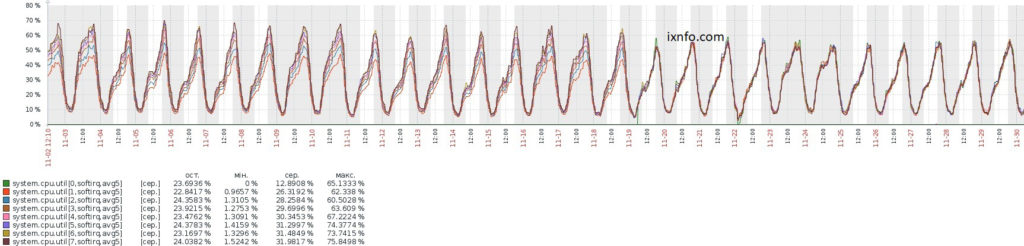
To prevent changes from being reset after a system restart, add the commands to /etc/rc.local:
/sbin/ethtool -L ens1f0 combined 8
/sbin/ethtool -L ens1f1 combined 8
echo 1 > /proc/irq/47/smp_affinity
echo 2 > /proc/irq/48/smp_affinity
echo 4 > /proc/irq/49/smp_affinity
echo 8 > /proc/irq/50/smp_affinity
echo 10 > /proc/irq/51/smp_affinity
echo 20 > /proc/irq/52/smp_affinity
echo 40 > /proc/irq/53/smp_affinity
echo 80 > /proc/irq/54/smp_affinity
echo 1 > /proc/irq/75/smp_affinity
echo 2 > /proc/irq/76/smp_affinity
echo 4 > /proc/irq/77/smp_affinity
echo 8 > /proc/irq/78/smp_affinity
echo 10 > /proc/irq/79/smp_affinity
echo 20 > /proc/irq/80/smp_affinity
echo 40 > /proc/irq/81/smp_affinity
echo 80 > /proc/irq/82/smp_affinity
You can view traffic statistics in real time:
apt install python3-pip
pip3 install netutils-linux
network-top -i 1 -n -1 --dev ens2,ens4
See also my articles:
- Configuring the Network in Linux
- Script to bind Intel NIC interrupts to processor cores
- Taskset – bind process to CPU cores
- How to find out on which NUMA node network interfaces
- How to distinguish physical processor cores from virtual
- Monitoring CPU usage in Zabbix
- Monitoring PPS (Packets Per Second) in Zabbix
- write error: Value too large for defined data type